













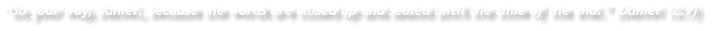




The ‘Trumpet Call’ at the Rapture
vs. the ‘Trumpet Plagues’ in Revelation
This page is to clarify the difference between the ‘trumpet call’ of Jesus, during
the rapture, and the ‘trumpet plagues’ in Revelation. They are not the same thing.
First of all, this is Jesus’ description of the ‘rapture’, which also means to ‘gather’.
Matthew 24:29-31 (Rapture)
“Immediately after the distress of those days 'the sun will be darkened,
and the moon will not give its light; the stars will fall from the sky,
and the heavenly bodies will be shaken.' 30 "At that time the sign of the
Son of Man will appear in the sky, and all the nations of the earth will mourn.
They will see the Son of Man coming on the clouds of the sky, with power
and great glory. 31 And he will send his angels with a loud trumpet call,
and they will gather his elect from the four winds, from one end of the
heavens to the other.”
Side note: There’s a wide-spread debate on what ‘distress’ or ‘tribulation’
Jesus is referring to but I address that on the ‘Matthew 24’ page. In short, there
are two different ‘elects’ in Matthew 24 because there are two different groups
‘selected’ in Revelation 7. First, there are 144,000 Jews who are chosen as a remnant
of David’s kingdom but must stay on earth and endure the trumpet plagues because
they didn’t believe in Jesus. Secondly, there is a ‘multitude’ who are gathered
immediately to heaven and stand before the Lamb, also in Revelation 7. Therefore,
Matthew 24 must have two ‘elects’ because it must match Revelation.
Anyway, regardless of anything before verse 29, it’s clear that the ‘signs’
in the sun, moon, and stars happen at the same time as the ‘trumpet call’ and
the ‘gathering’. Since the 6th Seal has the same exact signs in the sun, moon,
and stars, it has to be the same event. In other words, there couldn’t be two unique
events, both during end times, that match those descriptions separately. No way.
Thus, if the rapture in Matthew 24 matches the 6th Seal, it can’t possibly be the
7th trumpet because the trumpets can’t start until after the 7th Seal (Rev. 8:1).
Obviously, the 6th Seal is before the 7th Seal so the rapture is before any trumpet
plagues. And the trumpets can’t all happen at the same time (during the 7th Seal)
because the 7th Seal only last “about half an hour” and the 5th trumpet takes
5 months, alone.
Besides, the 7th trumpet is when the two witnesses ascend to heaven, in
Revelation 11, which doesn’t have anything to do with the multitude in Revelation 7.
The two witnesses prophesy in Jerusalem for 1260 days (42-months), so if the
7th trumpet was the rapture, then they would have to show up in Jerusalem, with
extraordinary powers, 3 ½ years a head of time. That would kind of give away the
surprise. Post-tribs try to get around that contradiction by symbolically explaining the
two witnesses as something else but Revelation clearly says they’re ‘men’. (more left)
Paul’s references to the ‘trumpet call’ at the rapture:
In Thessalonians, Paul uses the exact phrase, ‘trumpet call’, so it matches
Matthew 24 exactly. In this case, he was just assuring people that their lost loved
ones, who believed in Jesus, would not be forgotten but would meet them in the air.
In fact, they would go first. Paul’s description matches Jesus’ perfectly because
Jesus comes on ‘clouds of the sky’ to ‘gather His elect’.
1 Thessalonians 4:16 (NIV)
“For the Lord himself will come down from heaven, with a loud command,
with the voice of the archangel and with the trumpet call of God, and
the dead in Christ will rise first.”
Paul’s second reference was to explain ‘how’ we would meet Jesus in the air:
‘very fast’ and by changing to an ‘imperishable’ body, first.
1 Corinthians 15:51-52 (NIV)
“Listen, I tell you a mystery: We will not all sleep, but we will all be changed-
52 in a flash, in the twinkling of an eye, at the last trumpet. For the trumpet
will sound, the dead will be raised imperishable, and we will be changed.
Unfortunately, this is also the reference that some people use to say that the
rapture is the 7th Trumpet (because it obviously says ‘last trumpet’). However, that
theory doesn’t explain the timing of the other trumpets and their sequence to the
6th and 7th Seals, as I explained above.
In this rare case, I think it helps to go back to the KJV for clarity.
1 Corinthians 15:52 (KJV)
52 “In a moment, in the twinkling of an eye, at the last trump: for
the trumpet shall sound, and the dead shall be raised incorruptible,
and we shall be changed.”
Notice from the KJV, that the same word ‘trumpet’ translates differently (within
the same verse). I think that indicates that we will be changed at the last possible
‘note’ of the trumpet sound. In other words, a ‘twinkling of an eye’ is a lot shorter
than a ‘trumpet sound’ so Paul explained that we would be changed at the last instant
or ‘trump’. Besides, who can say if a ‘trumpet call’ is one sound or many notes?
Regardless, the ‘changing’ and the ‘gathering in the air’ happen at the ‘end’ of it.
Conclusion:
By comparing the ‘signs’ in the sun, moon, and stars in Matthew 24 to
the 6th Seal, it’s blatantly obvious when the rapture takes place in Revelation.
By simple deduction, we know that there’s a ‘trumpet call’ at the 6th Seal but it’s
left out in Revelation. Why would God do that? Solomon said, “It is the glory of
God to conceal a matter; to seek a matter out is the glory of kings.” (Proverbs 25:2)
When you think about it, Revelation would have easy to figure out, long ago,
if a trumpet was included in the 6th Seal. God has a way of hiding things in
plain sight until He wants them discovered. In any event, the evidence is clear now
because He has revealed the true meaning of the Seals and the ‘trumpet plagues’
must come afterwards. (Rev. 8:1)




 Related page:
Who are the Two Witnesses?
Related page:
Who are the Two Witnesses?

 Scripture taken from the HOLY BIBLE, NEW INTERNATIONAL VERSION. Copyright © 1973, 1978, 1984 by
International Bible Society. Used by permission of Zondervan Publishing House.
© Copyright 2010 - 2015 All rights reserved.
Daniel 11 Explained
(condensed ‘one page’ commentary)
‘Matthew 24’ Explained
(must match Revelation)
The ‘Seals’ Explained
(Revelation timeline revealed)
Seven Churches Explained
(Past & Present Church Prophecy)
Note: ‘Sitemap’ shows a complete list of all pages (by category).
‘Homepage’ gives 3 simple steps + timelines + summary.
Scripture taken from the HOLY BIBLE, NEW INTERNATIONAL VERSION. Copyright © 1973, 1978, 1984 by
International Bible Society. Used by permission of Zondervan Publishing House.
© Copyright 2010 - 2015 All rights reserved.
Daniel 11 Explained
(condensed ‘one page’ commentary)
‘Matthew 24’ Explained
(must match Revelation)
The ‘Seals’ Explained
(Revelation timeline revealed)
Seven Churches Explained
(Past & Present Church Prophecy)
Note: ‘Sitemap’ shows a complete list of all pages (by category).
‘Homepage’ gives 3 simple steps + timelines + summary.

 Current Events from Daniel 11 (matching the Middle East)
The
Abomination
(Daniel 11:31)
Current Events from Daniel 11 (matching the Middle East)
The
Abomination
(Daniel 11:31)
 done
Recent Events
ISIS - Saudi - Turkey
(Daniel 11: 24-27)
Final Events
to the Abomination
(Daniel 11: 28-30)
Shiites re-take Persia
+ America’s Role Begins
(Daniel 11: 21-23)
done
Recent Events
ISIS - Saudi - Turkey
(Daniel 11: 24-27)
Final Events
to the Abomination
(Daniel 11: 28-30)
Shiites re-take Persia
+ America’s Role Begins
(Daniel 11: 21-23)
 soon
soon
 done
done
 done
Proof of Rapture
(simplest explanation yet)
Video:
End Times Explained
(pre-trib rapture explained)
40 minutes
done
Proof of Rapture
(simplest explanation yet)
Video:
End Times Explained
(pre-trib rapture explained)
40 minutes
UA-32512179-1










